webpack原理
Webpack 最最核心的功能,一是使用适当 Loader 将任意类型文件转译为 JavaScript 代码,例如将 CSS 代码转译为 JS 字符串,将多媒体文件转译为 Base64 代码等;二是将这些经过 Loader 处理的文件资源合并、打包成向下兼容的产物文件。
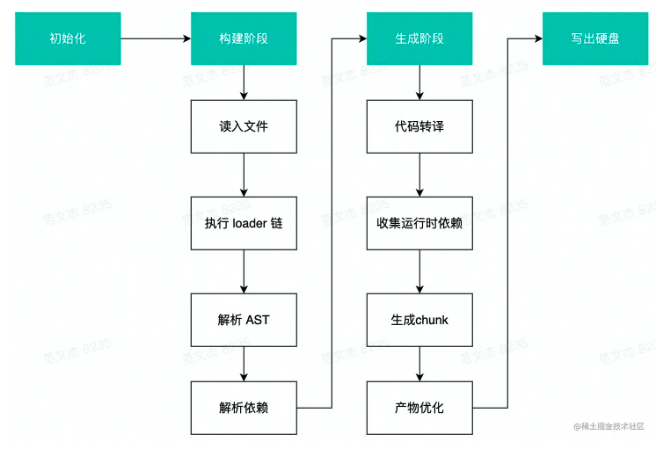
为了实现这些功能,Webpack 底层的工作流程大致可以总结为这么几个阶段:
初始化阶段
- 初始化参数:从配置文件、 配置对象、Shell 参数中读取,与默认配置结合得出最终的参数;
- 创建编译器对象:用上一步得到的参数创建 Compiler 对象;
- 初始化编译环境:包括注入内置插件、注册各种模块工厂、初始化 RuleSet 集合、加载配置的插件等;
- 开始编译:执行 compiler 对象的 run 方法,创建 Compilation 对象;
- 确定入口:根据配置中的 entry 找出所有的入口文件,调用 compilation.addEntry 将入口文件转换为 dependence 对象。
构建阶段
- 编译模块(make):从 entry 文件开始,调用 loader 将模块转译为标准 JS 内容,调用 JS 解析器将内容转换为 AST 对象,从中找出该模块依赖的模块,再 递归 处理这些依赖模块,直到所有入口依赖的文件都经过了本步骤的处理;
- 完成模块编译:上一步递归处理所有能触达到的模块后,得到了每个模块被翻译后的内容以及它们之间的依赖关系图,构建出完整的模块依赖关系图。
封装阶段
合并(seal):根据入口和模块之间的依赖关系,组装成一个个包含多个模块的 Chunk; 优化(optimization):对上述 Chunk 施加一系列优化操作,包括:tree-shaking、terser、scope-hoisting、压缩、Code Split 等; 写入文件系统(emitAssets):在确定好输出内容后,根据配置确定输出的路径和文件名,把文件内容写入到文件系统。
在这个过程中有不少可能造成性能问题的地方:
- 构建阶段:
- 首先需要将文件的相对引用路径转换为绝对路径,这个过程可能涉及多次 IO 操作,执行效率取决于 文件层次深度;
- 找到具体文件后,需要读入文件内容并调用 loader-runner 遍历 Loader 数组完成内容转译,这个过程需要执行较密集的 CPU 操作,执行效率取决于 Loader 的数量与复杂度;
- 需要将模块内容解析为 AST 结构,并遍历 AST 找出模块的依赖资源,这个过程同样需要较密集的 CPU 操作,执行效率取决于 代码复杂度;
- 递归处理依赖资源,执行效率取决于 模块数量。
- 封装阶段:
- 根据 splitChunks 配置、entry 配置、动态模块引用语句等,确定模块与 Chunk 的映射关系,其中 splitChunks 相关的分包算法非常复杂,涉及大量 CPU 计算;
- 根据 optimization 配置执行一系列产物优化操作,特别是 Terser 插件需要执行大量 AST 相关的运算,执行效率取决于 产物代码量;
- 等等。
可以看出,Webpack 需要执行非常密集的 IO 与 CPU 操作,计算成本高,再加上 Webpack 以及大多数组件都使用 JavaScript 编写,无法充分利用多核 CPU 能力,所以在中大型项性能通常表现较差。
不过,这些性能问题是可以被优化的
总结
Webpack 构建主流程中方方面面的原理,总结为:
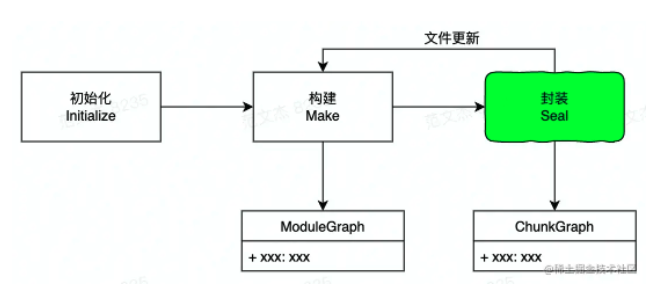
- Webpack 构建过程可以简单划分为 Init、Make、Seal 三个阶段;
- Init 阶段负责初始化 Webpack 内部若干插件与状态,逻辑比较简单;
- Make 阶段解决资源读入问题,这个阶段会从 Entry —— 入口模块开始,递归读入、解析所有模块内容,并根据模块之间的依赖关系构建 ModuleGraph —— 模块关系图对象;
- Seal 阶段更复杂:
- 一方面,根据 ModuleGraph 构建 ChunkGraph;
- 另一方面,开始遍历 ChunkGraph,转译每一个模块代码;
- 最后,将所有模块与模块运行时依赖合并为最终输出的 Bundle —— 资产文件